Entropy Bound is an interactive theatrical performance uniting humans, artificial intelligence and media.
“The holographic bound defines how much information can be contained in a specified region of space… The universal entropy bound defines how much information can be carried by a mass 𝓂 of diameter 𝑑.”
– Jacob D. Bekenstein, 1972
A woman incapable of forming long-term memories due to a brain injury becomes an early adopter of an AI brain implant device. The story evolves around her trying to find a way to relate to, and utilize the new technology inside her head by training it, and learning from it at the same time.


Accompanied by her family and friends, who have their own peculiarities, she tries to form new memories with the help of the implant, but inevitably starts to follow triggered associations and falls in a local minima of her unremembered memories.


Technological experiments aimed to imagine how such a device might look. A system prototype powering a hypothetical brain implant was built during the workshop.

The main input for the system is a live video feed, captured by a POV camera, worn by the actress.
Video is streamed to a number of real-time ML (Machine Learning) processors with the goal of recognizing objects, theatrical props and faces. Each processor produces semantic frame annotations by specifying recognized entities, their position on the frame, and recognition confidence levels.
Based on these frame annotations, a feature vector, describing frame contents is built for future frame comparisons.
Video stream and frame annotations are stored in the repo – the brain implant’s memory. The repo is designed in a way that any data stored there can be accessed at any time by any other module.
A “Scene Segmenter” module detects scene changes in the video stream in real-time, by utilizing semantic information from generated annotations. Scene segments are stored in the repo as well.
Finally, a separate module uses calculated feature vectors to query the repo for the scenes that most closely resemble the current frame. Therefore, the brain implant may ask its memory something like “give me 5 scenes from the past that look similar to what I’m seeing right now”.
Additionally, a brain implant user is able to add emotional context (using emoji) to video frames when forming memories.
When all components are live and operating, the live feed is being semantically annotated frame-by-frame, while being captured for storage, and analyzed for scenes based on the semantic context.
Scenes from the past are continuously retrieved from the storage for presentation onstage and act as evoked memories (associations). How far back we can go, and the comparison function, are both configurable.
In the words of the story, the brain implant triggers memories from the past that relate in some way to what is being currently observed.
Each system component is a separate module: a C++ or a Python app, some of them (the ML processors) are containerized using Docker.
For communication and video streaming, we used NDN over Layer2, thus all the machines were connected to the same LAN segment.


Video feed from the wearable lipstick camera is fed over SDI to the Capture TouchDesigner machine, where it is compressed and published over NDN using an NDN-RTC Out TOP built using NDN-RTC library specifically for this workshop. The Edge node and Repo machines are connected over NDN to the same LAN. The Edge node runs three Dockerized ML processors – OpenFace, YOLO1 and YOLO2 for faces, objects, and props recognition respectively. The Scene Segmenter as well as the Memory Trigger are running on the same machine.
The Edge node and the Repo fetch the NDN-RTC stream from the Capture machine. The Repo stores video frames and makes them available immediately for historical fetching. Frame annotations are published over NDN by the ann publisher module. Annotations are fetched by the Repo, Scene Segmenter, Memory Trigger, as well as by other modules.
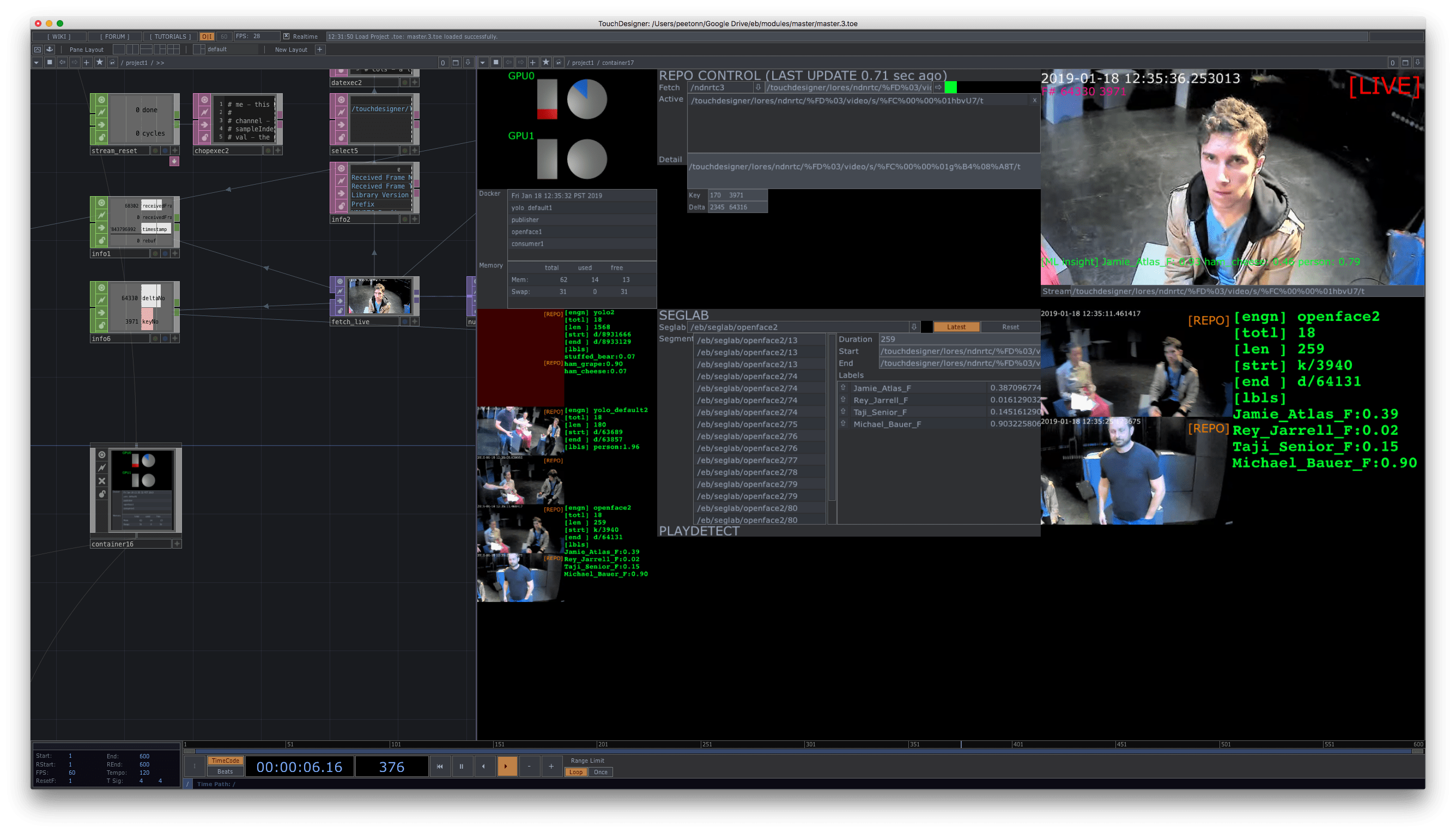
The video stream is also consumed by the Master and Viz machines. The former allows for real-time monitoring and control of the whole system: the Edge node and Repo statuses, detected scenes and triggered memories. The Viz machine performs compositing of the visuals (TRACE) that are being projected in space.
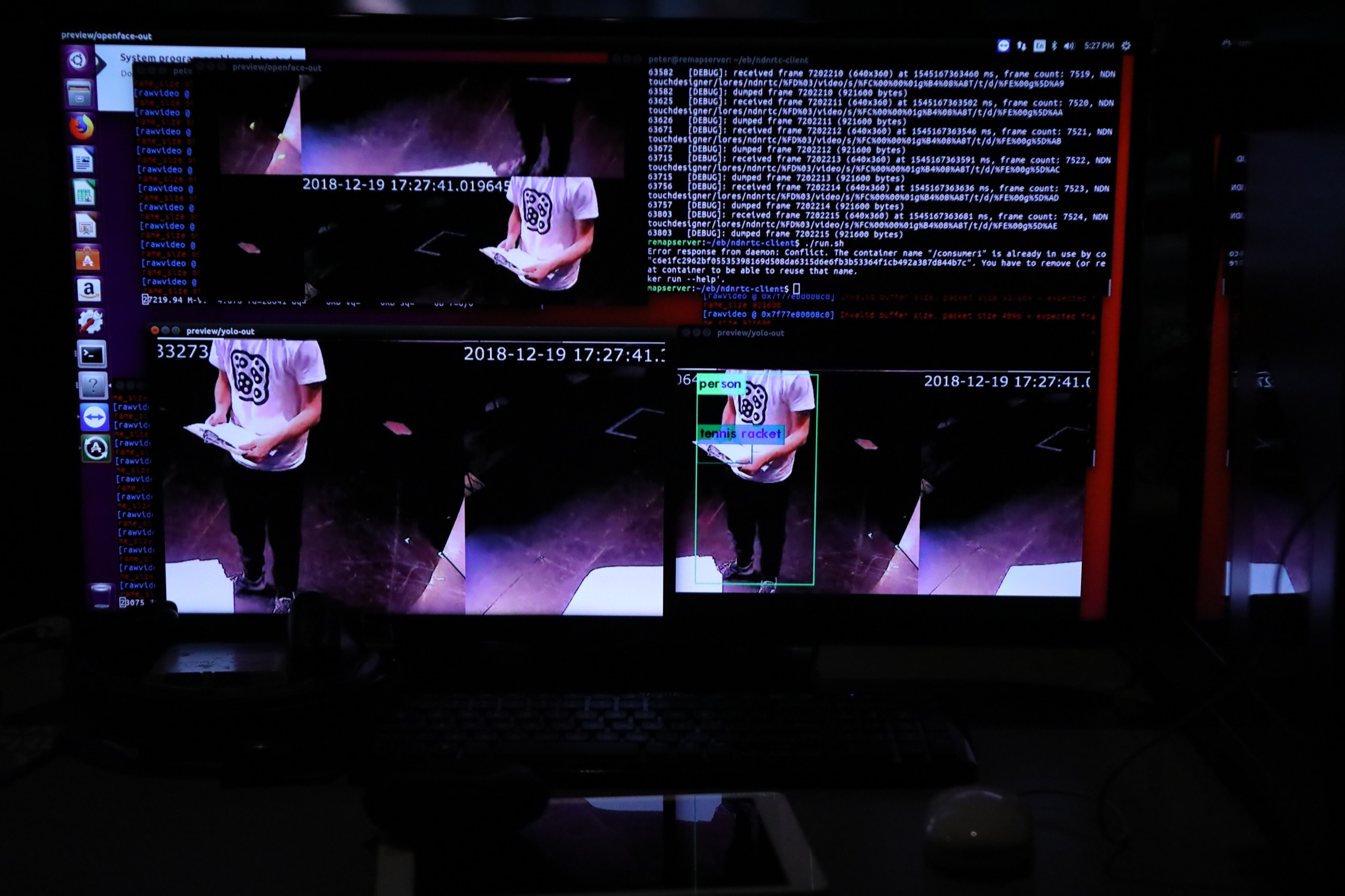
An additional Monitor machine is fetching ML annotations and detected scenes’ information.
This data is then being sent over WiFi to the “debug” Info laptop. The Info machine is outputting to a ceiling projection, in order that system performance may always be monitored by simply looking up at the sky. The Master node also sends start and end frames for detected scene segments to the Info machine for display.
The projection system includes a 10K projector and two 4K projectors. Composited and rendered visuals are streamed over NDI from the Viz node to the projection machine.
The 10K is focused to the upstage wall, while the two 4Ks cover two set pieces by the proscenium.
The workshop allowed us to experiment with, and explore the limits of, the technologies used.
Using NDN as the main communication network turned out to be successful.
The connection-less, data-centric nature of NDN allowed us to avoid many problems with low-latency data dissemination across multiple agents.
Since every data packet has a unique name, implementing the Repo was straightforward (RocksDB was used as a backend storage).
Some additional work needs to be done for ML part of the system, specifically scene detection and comparison.
TouchDesigner UI for the Master Node →
Ceiling projection of the Info node →
